CosineAnnealingLR-余弦退火调整学习率
余弦退火学习率调整策略的原理和应用.
原理
在神经网络训练的过程中, 随机梯度下降( Stochastic Gradient Descent, SGD ) 是一种常用的优化算法:
$$ \bm{x}_{t+1} = \bm{x}_t - \eta_t \nabla f_t (\bm{x}_t) $$
其中 $\eta_t$ 为学习率. 通常在训练刚开始时, 学习率较大以加快训练进程, 当模型趋近收敛时, 学习率较小避免振荡. 实际操作中, 有许多种学习率调整策略, Pytorch 中的 torch.optim.lr_scheduler 模块内集成了多种根据 epoch 调整 lr 的类可供选择, 本文主要介绍其中的两种 CosineAnnealingLR 和 CosineAnnealingWarmRestarts, 这两种方法都参考论文: SGDR: Stochastic Gradient Descent with Warm Restarts, 前者只实现了余弦部分, 后者为论文中提出的方法.
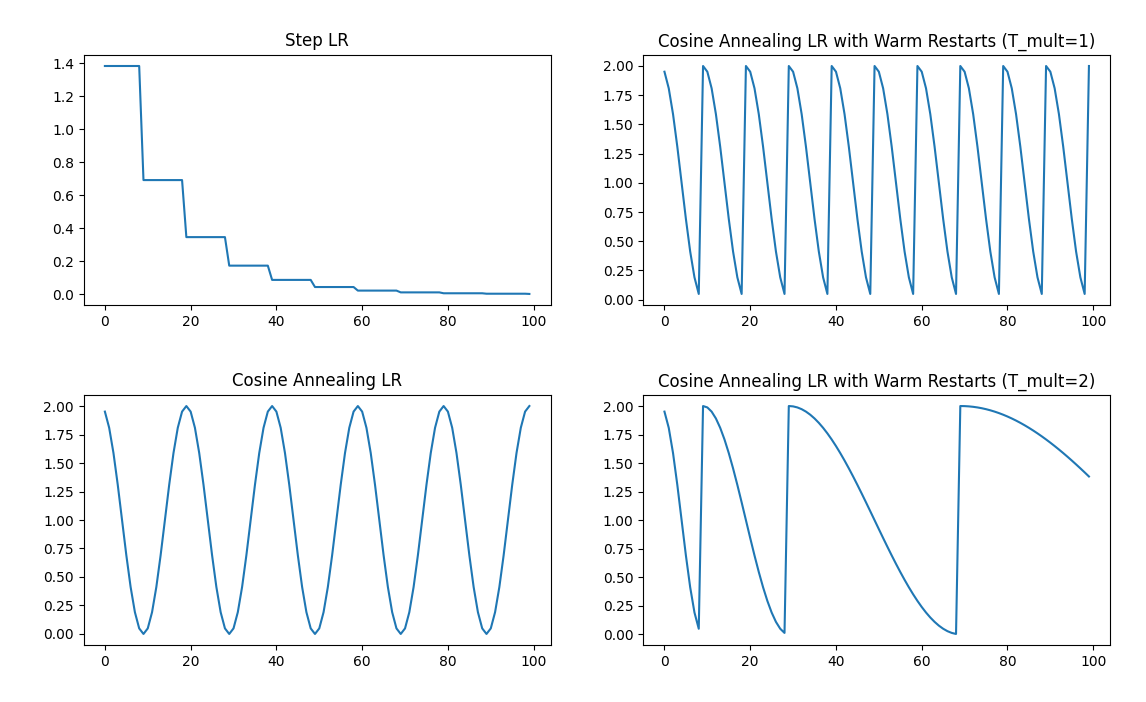
1. CosineAnnealingLR 余弦退火学习率
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)
这种方法调整的学习率随 epoch 的变化呈余弦曲线形式.
设 $T_{max}$ 为余弦周期, $T_{cur}$ 为当前周期数, 这个值通常为从开始到现在经过的 epoch 数, $[\eta_{min}, \eta_{max}]$ 为学习率的取值范围. 则该方法表达式为:
$$
\eta_t = \eta_{min} + \frac{1}{2} (\eta_{max} - \eta_{min}) \left( 1 + \cos{\left( \frac{T_{cur}}{T_{max}} \pi \right)} \right)
$$
当 $T_{cur}=0$ 时, $\eta_t=\eta_{max}$, 接着不断下降, 当 $T_{cur}=T_{max}$ 时, $\eta_t=\eta_{min}$, 然后开始上升, 如此循环往复.
2. CosineAnnealingWarmRestarts
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0)
这种方法在 CosineAnnealingLR 的基础上添加了 Restarts 策略. 这种策略下, 学习率变化不再是连续的余弦曲线, 而是由许多段 $0 \sim \pi$ 的余弦曲线相连, 每一段都被看成是一次新的 run, 包含了学习率从最大值 $\eta_{max}^i$ 经过 $T_{i}$ 个周期逐渐变化到最小值 $\eta_{min}^i$ 的过程, 其中 $i$ 为 run 的索引. 表达式为:
$$ \eta_t = \eta_{min}^i + \frac{1}{2} (\eta_{max}^i - \eta_{min}^i) \left( 1 + \cos{\left( \frac{T_{cur}}{T_{i}} \pi \right)} \right) $$
式中的 $T_{cur}$ 为从上一次 Restart 后经过的 epoch 数, 它可以取小数值.
当 $T_{cur}=0$ 时, $\eta_t=\eta_{max}^i$, 然后不断下降, 当 $T_{cur}=T_{i}$ 时, $\eta_t=\eta_{min}^i$, 紧接着下一个循环 Restart , 更新 $T_{cur}=0, i=i+1$.
由于每次 run 的参数是独立的, 因此可以根据 $i$ 来调整每次 run 的参数 $T_i, \eta_{max}^i, \eta_{min}^i$, 例如让 $T_i$ 逐渐增大, 让 $\eta_{max}^i, \eta_{min}^i$ 逐渐变小. Pytorch 的接口提供了 $T_{mult}$ 参数, 可以让 $T_i$ 按照 $T_{i+1}=T_i\times T_{mult}$ 的规律增长.
CosineAnnealingWarmRestarts 时, 模型表现会周期性变差, 表现最好的模型参数应当在最后一个 run 的结束处, 即 $\eta_t=\eta_{min}^i$ 时取得.3. StepLR
顺便介绍一下最常见的学习率调节方法 StepLR.
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
这种方法非常简单, 就是每经过 step_size 个周期, 更新 $\eta = \eta \times gamma$
4. 论文中的对比
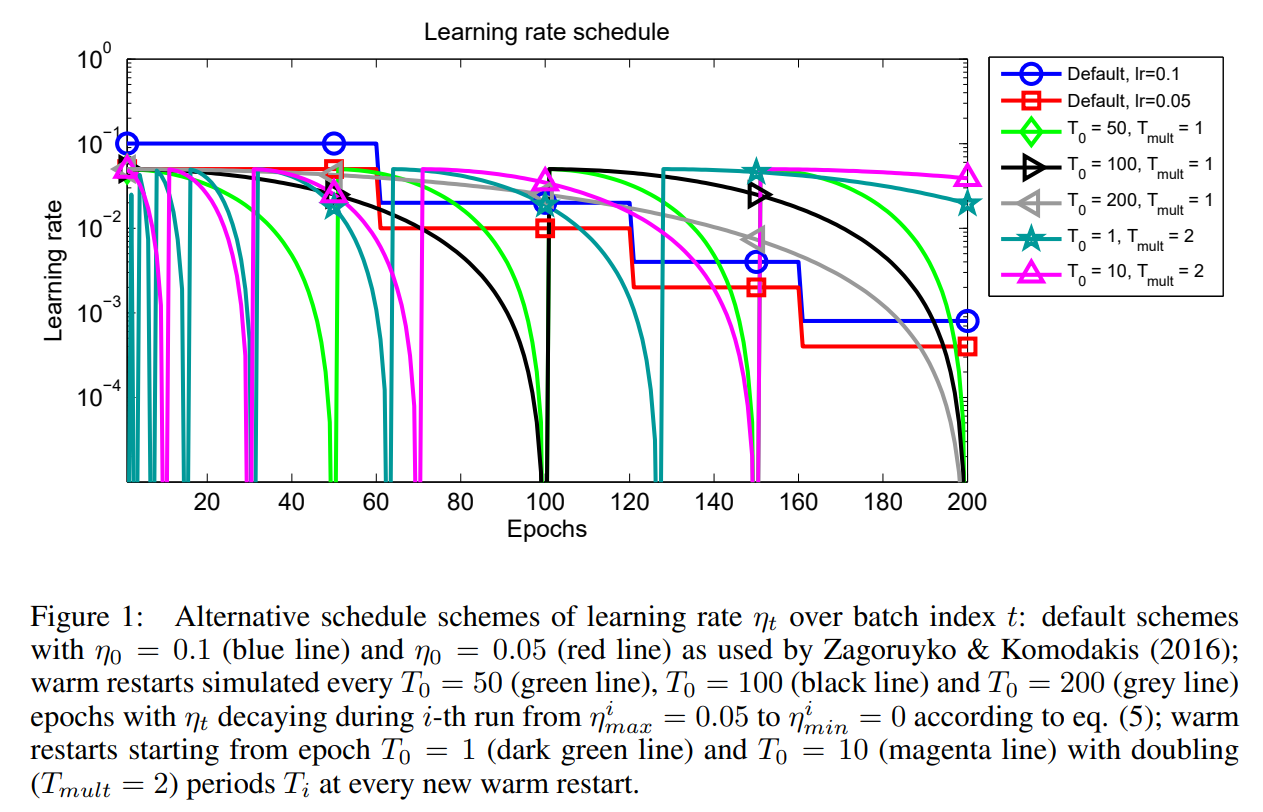
- 蓝色曲线: StepLR, $\eta_0=0.1$
- 红色曲线: StepLR, $\eta_0=0.05$
- 绿色曲线: Cosine Annealing with Warm Restarts, $T_0=50, T_{mult}=1$
- 黑色曲线: Cosine Annealing with Warm Restarts, $T_0=100, T_{mult}=1$
- 灰色曲线: Cosine Annealing with Warm Restarts, $T_0=200, T_{mult}=1$
- 深绿曲线: Cosine Annealing with Warm Restarts, $T_0=1, T_{mult}=2$
- 洋红曲线: Cosine Annealing with Warm Restarts, $T_0=10, T_{mult}=2$
论文经验性地指出, 使用 Cosine Annealing with Warm Restarts , 可以用 $ 1/2 \sim 1/4 $ 倍的其他方法所需 epochs, 达到与它们差不多甚至更好的性能.
Python 实验
可视化这几种策略的学习率变化曲线如下所示.
|
|